Top Microsoft Office 365 Service Delivery Management Best Practices
Microsoft Office 365 Performance
These articles are part of a series on Office 365 Service Delivery Management.
Understanding Office 365 Contracts
Modern Service Management with Microsoft Recommendations
Cloud Service Management Best Practices for Office 365
Understanding Office 365 Contracts
In this article we will cover a very important topic for organizations using Cloud services, especially Office 365. We are speaking about contracts, what guarantees they include, and how to optimize your relationship with Microsoft.
With Software as a service (SaaS) like Office 365, the role of the admin team has shifted dramatically from infrastructure support and maintenance to service management.
The purpose of IT Service Management is to manage end-user expectations, reduce the number of issues, reduce our mean time to repair, and verify the best possible service delivery to your users.
So let’s take a look at Microsoft contracts.
Microsoft Office 365 Contract Management
Contracting with Microsoft Office 365 offers you the best-in-class Collaboration SaaS application.
That comes with several guarantees in term of availability of the services from a Microsoft perspective.
A SLA is a kind of insurance against service disruption so the first thing to do is to understand the limitations of this insurance.
Basically, they concern:
- Anything happening outside of reasonable control (force majeure)
- Anything happening outside of their datacenter
- Anything that has been caused by your company (irrespective of Microsoft recommendations, bad configuration bandwidth,unauthorized actions, etc.)
- Any downtime happening during scheduled downtime
To be clear, the service delivered to your end-user is NOT guaranteed by Microsoft SLA. And that is completely normal as Microsoft is not running your Network, your ISV or anything inside your infrastructure.
Only the service delivered to the edge of their datacenter is guaranteed provided that you didn’t contribute to make it fail.
So now that we understand what is excluded, let’s understand what’s the famous 99.9% means for you.
Microsoft calculates a downtime ratio based on your total number of user minutes of use of the service.
The calculation is: [(User Minutes – Downtime Minutes) / User Minutes] *100

As downtime only counts for users that are impacted, you might surmise that you need a big incident to go under 99.9% of availability.
Let’s do a short calculation for a company with 10,000 users:
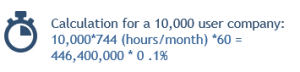
In order to breach the 99.9% SLA, you would need for example to have an outage of 44 640 user minutes of downtime per month. And that means an incident of almost 45 min for a 1000 of your users per month.
We now understand the general limitations of the contract and what is generally insured. Now let’s look at services.
Microsoft Services Guaranteed
Let’s start with Microsoft Exchange Online.
For your users and so for your ITSM, Exchange Online encompasses a wide range of actions including accessing mailboxes from Outlook, sending email, creating meetings, checking free/busy statuses, searching for mail in the mailbox, etc. But in the Microsoft SLA, the only service guaranteed for Exchange Online is the ability to send or receive email with Outlook Web Access.
Here we are speaking about availability only; not about Performance.
If the service is slow, it is still considered as up from an SLA prospective, even if your users might consider it down.
Any other Microsoft Exchange feature is excluded from the SLA.
Let’s continue with Skype for Business Online cause things have changed a lot recently!
Until recently, there were 3 types of SLA for Skype for Business:
- The first is based on the ability for a user to see presence status, conduct instant messaging conversations, or initiate online meetings.
- The second is based PSTN Calling and Conferencing, guaranteeing the ability of a user to initiate a PSTN call or conference.
- And finally, the last SLA on Skype is about Voice quality.
But now, only the first SLA is maintained. The 2 others have been transferred to Microsoft Teams. So if you are still on Skype, you need to know that your ability to do PSTN call and their Voice quality is not guaranteed anymore.
Let’s continue with Microsoft Teams.
The calculation is the same but only on the ability for a user to see presence status, conduct instant messaging conversation or initiate an online meeting.
As mentioned, Microsoft has now added the SLAs they were providing on Skype for Business before.
So you have now on top of that:
- Initiate a PSTN or dial into conference audio via the PSTN
- Voice quality only if you use a Microsoft certified IP Desk phone on wired Ethernet and if network issues were found on the Microsoft network.
For voice quality, Microsoft basically calculates a Network MOS that predicts what would be the end-user call quality ranking.
They then check how long these poor-quality calls last and provide a ratio with the total number of user minutes in a month.
The network MOS is based on a constant measurement of the roundtrip time, packet loss, Jitter and concealment factors.
It means that any voice call, video sharing, meeting initiate from a Teams client on a computer or a phone is not part of the SLA.
If we look at OneDrive, the only service guaranteed is the ability for a user to view or edit files that are stored on their personal OneDrive for Business Storage.
If we look at Microsoft SharePoint Online, the SLA is a bit the same and consist in the ability for a user to read or write any portion of a SharePoint Online site collection for which they have appropriate permissions.
At this point, to maximize your relationship with Microsoft we would recommend:
- Read your contract and make sure you differentiate what Microsoft promises you and what you are promising to your business lines.
- Microsoft SLAs are a good starting point but cannot be a basis for your Service Delivery
- 90% of the time, a user’s performance issue root cause will be found outside Microsoft range of responsibility. So, you need to implement Cloud Service Delivery best practices to deal with the end-to-end service delivery to your end-users.
But let’s say that you have identified issues and you want to talk with Microsoft. What is required for that?
How To Let Microsoft Help You
To help you, Microsoft needs to have a certain number of statistics and facts:
- A detailed description of the incident
- Information regarding time and duration of the downtime
- Number of locations and affected users
- Description of your attempts to resolve the incident
The question is then, how do you collect this information?
How do you know that the service was possibly down on a Sunday at 3 am if you are not constantly monitoring it?
These questions point to the necessity of monitoring, from a Microsoft service perspective and from an end-user perspective.
We would recommend here to not forget to report your outages and performance issues. But, you will you need statistics.
There is an easy way and a hard way to get those statistics.
- The hard way – Deploy and maintain complex scripts running from every locations, alerting you when an issue arises and feeding databases that can be easily used to share the data with Microsoft.
- The easy way -Or you can use third-party solution tools, like Martello’s Vantage DX for Office 365.
The Martello Robot Users are small Windows services that you can install anywhere you want. The Robot Users act exactly as a user would do on Office 365, performing complex end-user scenarios.
They alert you in case of any availability and performance issues and provide every data you need through PowerBI or any other BI Solution.
Finally, before contacting Microsoft, go through incident analysis to make sure that you are not responsible for what is happening.
Here is an example of Exchange Online Service Level dashboard that you can easily get on PowerBI with the Martello Robot User data.
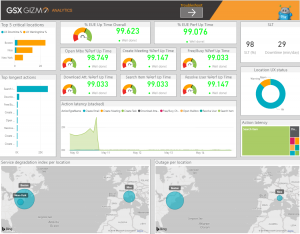
What we can see here is that you can have the service delivered per location, but also per actions that your users are performing.
With the convenience of the Martello Service level dashboard, you not only have the service availability information, but also vital information about the performance you deliver and reach on a daily or monthly basis.
It is also a perfect way to share your data with Microsoft to help them helping you.
We built these dashboards using Microsoft and Gartner recommendations that we are now about to detail.
Now that we’ve seen the benefits and limitations of the contract with Microsoft, we understand that you need to go a step further if you want to ensure Service delivery to your end-users.
Modern Service Management with Microsoft Recommendations
Now let’s have a closer look at Microsoft recommendations for service management.
Microsoft states in their blog, the “Service Management should be a focus for all customers”. Microsoft defines Modern Service Management as a way to ensure business consumption and productivity.
This model is based on 4 pillars. Let’s start with Service desk.
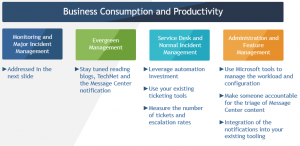
Service Desk and Normal Incident Management needs processes in place to support your users in their day-to-day lives.
For that Microsoft recommends leveraging automation investment from the Office 365 service.
They also recommend using your existing ticketing tools to measure the number of tickets and escalation rates in order to focus on the right areas.
Regarding Administration and Feature Management, use every tool that Microsoft provides to manage the workload and configuration.
The Evergreen Management defines the processes in place to test, implement and be ready for the continuous improvement that Microsoft implements into Office 365 regularly.
To manage that you should make someone accountable, on a daily basis, for the triage of Message Center content and the integration of the notifications into your existing tooling.
You should stay updated by reading blogs, technets and the message center notifications, to understand when new features will be implemented and how they could impact your end-user experience.
Let’s focus now on monitoring and major incident management.
Monitoring and Major Incident Management
It defines the processes that ensure the detection and troubleshooting of end-user service delivery issue, regardless of root cause.
The main challenge here is to bring back visibility on the services that you actually deliver to your end-users.
For that Microsoft recommends integrating the Office 365 service health dashboard notifications into your existing incident workflow and tools.

Then, to combine this information with end-to-end monitoring scenarios that will measure the true end-user experience for each main capability of Office 365, from where your users are.
By Capabilities, Microsoft defines, for example for Microsoft Exchange:
- Login via Outlook
- Mail flow
- Mobile Sync
For SharePoint Online or OneDrive.
- Login
- Download / upload document
As we can see, Microsoft clearly states that you need to have visibility on what users are able to accomplish with Office 365.
To complete this first set of recommendation, we would recommend that you:
- Find the right balance between measuring too many complex scenarios that would quickly become unmanageable, and not measuring enough, thus decreasing the visibility you would have on the service.
- Check performance also; measuring availability is not enough.
- Measure whatever is creating the most user complaints and tickets to your Service Desks.
If we take the example of Exchange Online again, you would then also include:
- The availability and performance of creating meetings, and use of the free/busy feature
- The availability and performance of searching through a mailbox
- The availability and performance of downloading an attachment
That would give a first good step for your Exchange Service Delivery.
As we already mentioned, the Martello Robot Users have been designed to perform the end-user transactions you need to measure.
That is why Martello is a Microsoft CoSell prioritized solution, and has been approved by Microsoft to deliver our solution both the Azure MarketPlace and the Office 365 Appsource.
To finish our discussion of the Microsoft recommendation about Office 365 Service Management, it is also interesting to understand how they are organized to manage the incidents and communicate on them.
Response to Incidents: Microsoft Organization
Within the Microsoft Office 365 organization, you have multiple teams that work together to prevent and communicate about service outages.

For that you have incident managers that have deep expertise in their relevant area. They determine the scope of outage and the root cause, then go through incident resolution.
You have communication managers that also have a deep expertise that coordinate and provide information across internal teams and post customer facing communication to the service health dashboard.
You then have support that are technical resources, providing 24/7 customer phone and web support.
And finally, you have service account management that are account representative and that can escalate tickets and provide rapid on-site support.
Below you can see the communication process Microsoft follows for each incident.
You don’t have to entirely replicate the Microsoft Service Incident organization, but it gives you a good staring basis on how to be organized, especially for large organizations.
This concludes our article on Microsoft recommendations for Modern Service Management of Office 365.
But Microsoft is not the only SaaS provider on the planet, and best practices for Cloud Service delivery have been developed and refined for many years.
Cloud Service Management Best Practices for Office 365
Now let’s have a closer look at best practices for Office 365 service management.
ITSM represents how IT manages, operates and transitions technology but also designs services and manages risks within the organization.
You certainly have already seen what service strategy, service design, service transition, service operation, or service incidents are.
They are clearly defined in ITIL processes, and I would warmly recommend you read about these processes if you haven’t started to implement these best practices for service management.
However, even clearly defined, these processes are facing serious challenges with Cloud Service Delivery.
In term of service strategy, one of your goals is to avoid risks of Shadow IT.
- For that you need to understand the use of the current solution the overall business needs and anticipating new services.
- Regular surveys among your employee, and public cloud services offering must be analyzed by your team.
When you think of service design and service operation, Software as a Service can be a headache.
- The challenge is to first define which service you want to manage.
In a previous article, we’ve seen that even for a simple Exchange Online environment, the notion of service can be very versatile.
- Then you need to define Service Level Target instead of SLA for these services.
Service Level Targets are better here, because they’re based on best effort and are not correlated with penalties.
You cannot take the risk of an SLA when you are not controlling the entire route of the service to the end-user.
Service Level Targets should be defined with the business lines at the location level (per country or region) and should not forget your mobile user. That is why you need to have a way to measure the mobile experience when it makes sense.
Defining SLT will enable you to start working on continuous service improvement, pinpointing the issues and justifying investment and success in service delivery
Regarding Service Transition and Change Management, the continuous migration of on-premises devices to mobile ones and the access to hybrid cloud system clearly complicates the job of IT administrators.
- To face that challenge, you should ensure the monitoring of the health and usage of your complex hybrid identities management.
The correlation between hybrid CMS and SaaS end-user service delivery is critical to manage.
Service Improvement is now even harder to reach than before because you can only improve what you can measure.
? For that, you need to implement a way to continuously measure the end-user service that is really delivered to your locations.
We’ve already explained how you can do that with Martello Robot Users.
Finally, regarding Service Incident and Service Desk, we’ve already seen what Microsoft is recommending and how Martello can really help you on that topic.
We would just stress a few additional recommendations here.
- You need to correlate the end-to-end user experience with the health of every component that can impact it, including the Microsoft Service Health Dashboard.
- You need to determine quickly if it is a local or tenant-wide issue.
- You need to know if anything that can impact the end-user experience is having trouble and then immediately share the information with the right team to fix the situation.
That will drastically reduce the mean time to repair and clearly improve the whole process of incident resolution and incident assignment, enabling better incident analysis and evaluation and the creation of a knowledge base.
Now that we’ve covered the main aspect of IT Service Management and what to put in place to face the Cloud delivery challenges, it is important to focus on how to set the right target for your service delivery.
Define Service Availability & Performance Level Target
We’ve already seen that defining the right services, based on user capabilities can be a challenge but is important to do.
Next is to define what level of service we want to reach.
From a user perspective, the notion of availability and performance are really intertwined.
Something too slow to use quickly becomes an availability issue for them.
So now we have to define what level of availability and performance we want to define in our Service Level Target and how to put them in place.
- First you need a way to test continuously the service you want to provide.
Again, one of the best way to do that is to use Martello’s Vantage DX.
The purpose is to define baseline in term of availability and performance, on a stable environment, at the location level action per action.
These baselines should recognize pattern of utilization. Usage varies during the day, the week the month and even the year.
- With these baselines you can start to define threshold on service delivery for alerting purposes.
Being alerted on any service degradation allow you to react quickly and fix issues before they really impact your users.
- Now you can calculate a target in term of minutes downtime per month that provides a good balance between the necessary business needs and the resources you have.
For example:
- Service true availability target at 98%
- Service Level Target Latency Threshold at for example 500 milliseconds to download a 1MB document.
- Service performance target at for example 80%. It represents the percentage of the time where this service latency is below a certain threshold.
So now that we have these Service Level Targets in place, you can really measure their achievement and enforce them.
Here comes the Service Capability monitoring.
Implementation of Service Capability Monitoring
It defines the ability of your own environment to deliver the cloud service.
Your environment is of course your hybrid component, your network, your internal applications using the cloud service and generally everything that can impact the end-user experience.
- What’s critical here is to be able to measure and correlate the information.
- For that you should have a single pane of glass that breach silos of your IT environments and display, in real-time, the health and main usage statistics of every component that can impact your Service Level Target.
We have pretty much covered the essential point of Service Delivery Management when it comes to SaaS application like Office 365. Learn more about maximizing the Microsoft 365 user experience by downloading our eBook today!


